
O Que Está no Interior do Cérebro do AlphaZero?
Na primeira parte deste artigo eu descrevi como o AlphaZero calcula variantes. Nesta parte eu irei cobrir como é que este aprende, por si mesmo, a jogar xadrez.
Eu terei de ignorar alguns detalhes, mas espero que ainda assim haja o suficiente para te dar uma melhor compreensão de como o AlphaZero funciona.
No interior do AlphaZero
Saltemos imediatamente para o coração da questão. A aprendizagem do AlphaZero tem lugar usando uma rede neutral, que pode ser visualizada da seguinte maneira:
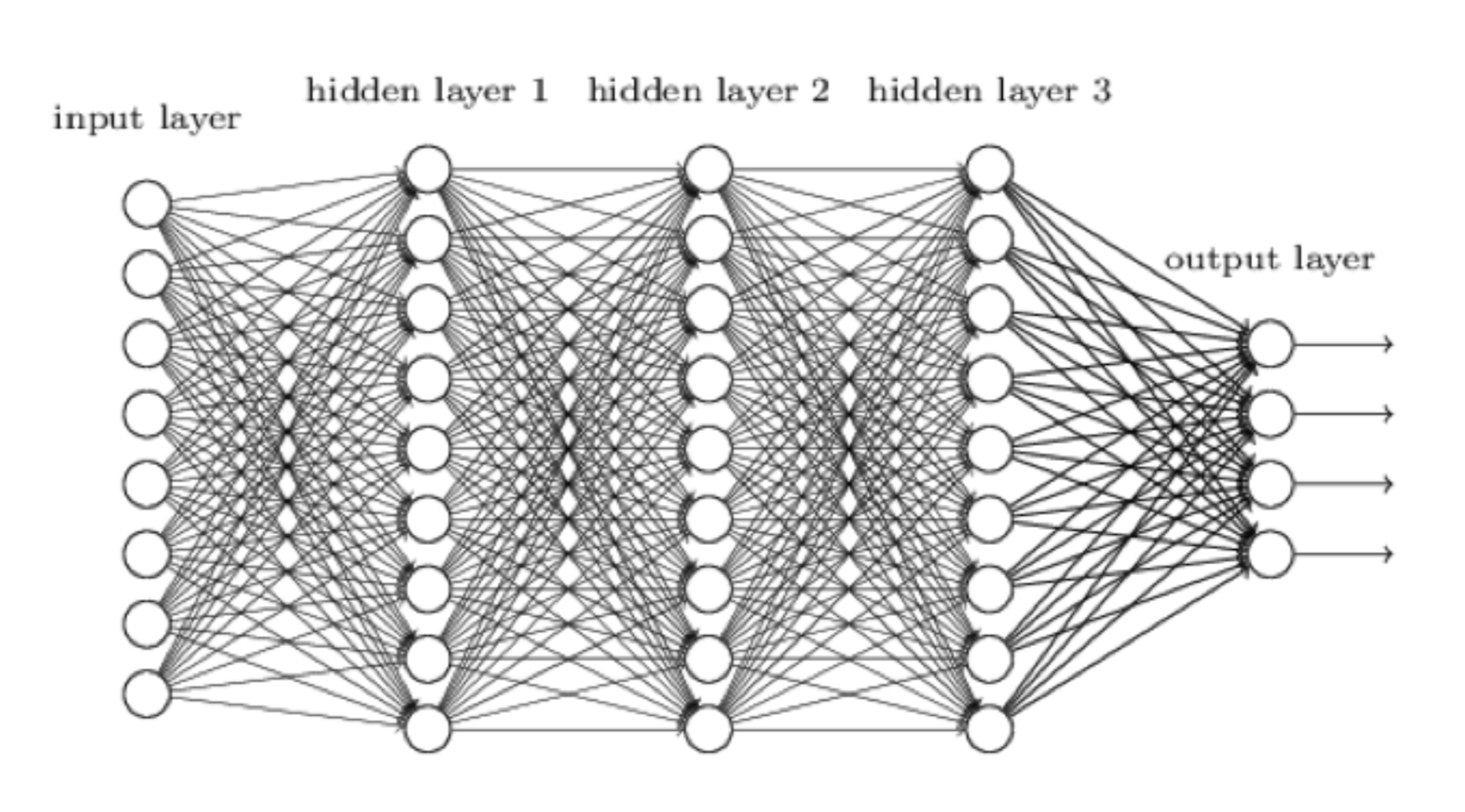
Uma rede neural é a nossa tentativa de fazer com que um sistema informático funcione mais como o cérebro humano e menos, bem, como um computador. A condição (input), i.e., a posição corrente no tabuleiro, começa do lado esquerdo. Esta é processada pela primeira camada de neurônios, cada um dos quais envia então o seu resultado (output) para cada neurônio na camada seguinte e assim por diante, até à camada de neurônios mais à direita fazer o seu trabalho e produzir o resultado final. No AlphaZero, este resultado (output) tem duas partes:
- Uma avaliação da posição que lhe foi dada.
- Uma avaliação de cada lance legal possível na posição.
Hey, o AlphaZero já soa como um jogador de xadrez: "As Brancas estão aqui um pouco melhor, e Bg5 ou h4 parecem ser lances bons!"
 Portanto estes neurônios devem ser uns diabinhos espertos, não é verdade? Um neurônio é de facto uma unidade de processamento muito simples (esta pode ser em forma de programas ou equipamento) que aceita um número de condições (inputs), multiplica cada uma por um determinado 'peso' [um peso é um valor atribuído que pode ser maior ou menor de acordo com a importância], soma as respostas e depois aplica uma assim chamada função de ativação que produz um resultado, tipicamente num intervalo de 0 a 1. Uma coisa a considerar é que o produto dum neurônio depende potencialmente de cada outro neurônio antecedente na rede, o que permite à rede de capturar subtilezas, tais como numa posição em que o rei das Brancas está a salvo depois de fazer roque, mas depois de h3 a avaliação muda uma vez que as Pretas podem abrir a coluna-g com g7-g5-g4.
Portanto estes neurônios devem ser uns diabinhos espertos, não é verdade? Um neurônio é de facto uma unidade de processamento muito simples (esta pode ser em forma de programas ou equipamento) que aceita um número de condições (inputs), multiplica cada uma por um determinado 'peso' [um peso é um valor atribuído que pode ser maior ou menor de acordo com a importância], soma as respostas e depois aplica uma assim chamada função de ativação que produz um resultado, tipicamente num intervalo de 0 a 1. Uma coisa a considerar é que o produto dum neurônio depende potencialmente de cada outro neurônio antecedente na rede, o que permite à rede de capturar subtilezas, tais como numa posição em que o rei das Brancas está a salvo depois de fazer roque, mas depois de h3 a avaliação muda uma vez que as Pretas podem abrir a coluna-g com g7-g5-g4.
Baseado nos dados publicados para o AlphaGo Zero (o predecessor do AlphaZero que joga Go) a rede neural do AlphaZero tem provavelmente cerca de 80 camadas, e centenas de milhares de neurônios. Faz a aritmética e compreendes que isto significa centenas de milhões de 'pesos.' Os pesos são importantes porque o treino da rede (também chamada aprendizagem) é uma questão de atribuir valores aos pesos de modo a que a rede jogue bem xadrez. Imagina que existe um neurônio que durante a aprendizagem assumiu o papel de avaliar a segurança do rei. Este recebe informações de todos os neurônios precedentes na rede e aprende quais os pesos a lhes atribuir. Se o AlphaZero apanha mate depois de mover todos os seus peões em frente do seu rei, este ajustará os valores dos pesos para reduzir a possibilidade de fazer novamente este erro.
Como o AlphaZero Aprende
O AlphaZero começa como uma lousa em branco, uma grande rede neural com pesos aleatórios. Este foi desenhado para aprender como jogar partidas de dois-jogadores, de lances-alternados, mas não sabe absolutamente nada sobre qualquer jogo em particular, muito da mesma forma que nós nascemos com uma vasta capacidade de aprender uma língua, mas sem conhecimento de qualquer língua em particular.
O primeiro passo foi de dar ao AlphaZero as regras de xadrez. Isto quer dizer que agora este pode jogar ao acaso, mas pelo menos faz lances legais. O próximo passo natural pareceria ser de o deixar aprender com partidas de mestre, uma técnica chamada aprendizagem supervisada. No entanto isso teria resultado com que o AlphaZero aprendesse simplesmente como jogar xadrez, com todas as suas imperfeições, portanto a equipa da Google escolheu usar em vez disso uma abordagem mais ambiciosa chamada aprendizagem reforçada. Isto quer dizer que deixaram o AlphaZero jogar milhões de partidas contra si mesmo. Após cada partida este faria pequenos ajustes nos seus pesos para tentar codificar (i.e. recordar-se) o que tinha dado bom resultado e o que não deu.
Quando este começou este processo de aprendizagem, o AlphaZero conseguia somente executar lances aleatórios e tudo o que sabia era que dar xeque-mate é o objetivo do jogo. Imagina tentar aprender princípios tais como controlo central ou o ataque minoritário, simplesmente a partir de quem deu xeque-mate a quem no final da partida! Durante este período de aprendizagem, o progresso do AlphaZero foi medido ao jogar torneios de um-lance-por-segundo com o Stockfish, e as prévias versões de si mesmo. Parece absolutamente incrível, mas o AlphaZero depois de duas horas a jogar contra si mesmo tinha aprendido o suficiente sobre xadrez para exceder o rating do Stockfish, ao mesmo tempo que examinava somente cerca de 0,1 porcento do número de posições que o Stockfish examinava.
Enquanto que isto é absolutamente fantástico, recorda-te que a humanidade aprendeu xadrez duma forma semelhante. Durante séculos, milhões de seres humanos têm jogado xadrez, usando os nossos cérebros para aprender mais sobre este jogo, como um gigantesco computador multi-processador baseado em carbono. Nós aprendemos por tentativa e erro a jogar no centro, a colocar torres nas colunas abertas, atacar correntes de peões na base, etc. Isto foi também o que o AlphaZero teve de fazer. Seria fascinante ver as 44 milhões de partidas que jogou contra si mesmo. Pergunto-me em qual delas é que ele teria descoberto o ataque minoritário?
Como o AlphaZero Joga Xadrez
Até agora nós vimos como o AlphaZero treina a sua rede neural de modo a poder avaliar uma dada posição de xadrez e determinar quais os lances que têm uma maior probabilidade de serem bons (sem calcular coisa nenhuma).
Aqui está mais alguma terminologia: a parte da rede que avalia posições é chamada a rede de valores (value network), enquanto que a parte que "recomenda lances" é chamada a rede de diretrizes (policy network). Agora vejamos como é que estas redes ajudam o AlphaZero atualmente a jogar xadrez.
Recorda-te que o grande problema no xadrez é a explosão de variantes. Para calcular com somente dois lances de antecedência a partir da posição de abertura envolve olhar para cerca de 150.000 posições, e este número cresce exponencialmente com cada lance que fores mais além. O AlphaZero reduz o número de variantes para que olhar ao considerar só aqueles lances que a sua rede de diretrizes recomenda. Este utiliza também a sua rede de valores para parar de pesquisar mais a fundo ao longo das linhas cujas avaliações sugerem que elas estão claramente decididas (vencidas/perdidas).
Digamos que existem em média três lances razoáveis possíveis, de acordo com a rede de diretrizes. Então à modesta taxa de 80.000 posições por segundo empregada pelo AlphaZero, este poderia olhar para cerca de sete lances de antecedência completos num minuto. Junta a isto a aplicação da sua avaliação instintiva oferecida pela sua rede de valores nas posições em formato de folha no fim das variantes que pesquisa, e tu tens uma máquina de jogar xadrez de facto muito poderosa.
O Equipamento que o AlphaZero Utiliza
Sem surpresa a rede neutral do AlphaZero funciona num equipamento especializado da Google, chamado tensor processing units (TPU). O AlphaZero utiliza 5.000 TPU de primeira geração para criar as partidas contra si mesmo, que são usadas para treinar a rede, e 64 TPU de segunda geração para fazer o treino atual. Esta é uma quantidade gigante de poder computacional. Para efetivamente jogar xadrez, só quatro TPU foram utilizados.
Porque é que a Google não utilizou também os outros 5.060 TPU? Provavelmente para mostrar que o AlphaZero não necessita de equipamento massivo para funcionar efetivamente.

Os 'tensor processing units' (TPU) da Google.
À medida que uma rede neural propaga valores entre as suas camadas, cada condição (input) para cada neurônio é multiplicado por um certo peso, naquilo que é essencialmente uma matriz de multiplicação (lembras isso da escola?). O TPU foi desenhado pela Google puramente para o treino e funcionamento de redes neurais, e portanto especializa-se em executar multiplicação de matrizes. Uma operação de multiplicação de matriz que requereria a um CPU regular no teu laptop uma longa série de cálculos, um TPU consegue fazer num único ciclo de relógio (e um TPU de primeira geração executa 700 milhões de ciclos por segundo). Imagina uma máquina numa fábrica que consegue colocar tampas em 100 garrafas de refrigerante ao mesmo tempo, vs alguma pobre alma que as coloca uma de cada vez.
AlphaZero vs Stockfish
Após quatro horas de treino, o rating do AlphaZero tinha excedido aquele do Stockfish. Este treinou por cinco horas mais, mas efectuou pouca ou nenhuma melhoria neste tempo (sim, isto é interessante por si só, mas os investigadores não ofereceram mais informação que permitisse uma interpretação). Nesta altura os dois jogaram um confronto de 100-partidas, um lance por minuto, que o AlphaZero venceu por 64-36 sem derrotas. Isto parece esmagador, mas de facto corresponde somente a uma diferença de 100 pontos de rating Elo. Muito tem sido debatido sobre a igualdade, ou falta desta, deste confronto. Foi recusado ao Stockfish o seu livro de aberturas, que é típico em confrontos entre computadores. O Stockfish utilizou 64 'thread,' que sugere que estava a funcionar num PC muito poderoso, mas utilizou simplesmente um tamanho de 'hash' modesto de 1 GB. Em contrapartida, o AlphaZero tinha 5.060 TPU ao seu dispor, mas só usou quatro deles no confronto.
Muitas pessoas propuseram como criar um confronto justo entre os dois, mas isto não é realmente possível, uma vez que eles dependem de equipamento radicalmente diferente. Uma corrida entre uma pessoa e um cavalo não seria transformada em "justa" ao permitir somente o uso de duas pernas.
O que é inegável, e extraordinário, é que a combinação de equipamento e 'software' do AlphaZero conseguiu aprender, em quatro horas, como avaliar posições e lances de xadrez melhor do que o altamente sofisticado Stockfish.
Se tu ainda estás a pensar no tamanho da tabela de 'hash' do Stockfish, tu estás de facto a perder de vista a importância do que aconteceu. Pensa no seguinte: mesmo que o AlphaZero tivesse perdido com o Stockfish por uma pontuação idêntica, a façanha do AlphaZero teria sido ainda assim somente um pouco menos fantástica.
Eu Quero AlphaZero No Meu Laptop!
Na verdade não queres! O AlphaZero treina redes neurais. O que tu na verdade queres é a rede neural com que o AlphaZero se treinou para jogar xadrez. Da mesma maneira que tu queres um médico para olhar para o teu dedo inchado, em vez duma universidade médica. Sem dúvida que esta rede neural foi copiada para disco enquanto outras tarefas foram designadas para os TPU que a treinavam. Se a estrutura da rede e os pesos fossem publicados, poderia ser possível, pelo menos em teoria, recriar a rede de jogar xadrez do AlphaZero num laptop, mas o seu desempenho não estaria à altura daquilo que pode ser alcançado com o equipamento especializado da Google.
Até que ponto ficaria aproximado? Façamos alguns alguns cálculos por alto. A parte do teu computador que está mais bem adaptada aos cálculos que o AlphaZero desempenha é o GPU ou unidade de processamento de gráficos. Isto pode parecer estranho, mas os gráficos são gerados por matrizes de multiplicação, que é também exatamente o que uma rede neural requer. A Google calcula que o seu TPU é cerca de 20 vezes mais rápido do que um GPU contemporâneo, portanto a máquina de 4-TPU que derrotou o Stockfish depende em cerca de 80 vezes mais poder do que um PC ordinário. Portanto de momento, isto está para além do utilizador doméstico.
Uma revolução está a ter lugar no campo da inteligência artificial, onde redes neurais estão a ser utilizadas para atacar problemas que eram previamente vistos como demasiado complexos para uma abordagem computacional. A abordagem generalizada do AlphaZero permitiu-lhe ensinar-se a si mesmo a compreender xadrez (não somente a calcular variantes) bastante melhor do que qualquer abordagem que seja específica ao xadrez foi capaz. Oh, e conseguiu fazer isso para o Go e Shogi também, jogos de tabuleiro com uma complexidade computacional mais alta do que o xadrez. É muito improvável que a Google estará interessada em avançar o projecto de xadrez mais além—esta irá colocar a sua mira em problemas mais desafiantes e que tenham valor.
Portanto o que significa tudo isto para o xadrez como nós o conhecemos? Representa um passo gigantesco que um computador pode agora ensinar-se a si mesmo a jogar xadrez a um tão alto nível, dependendo mais duma aprendizagem de tipo humano do que na tradicional, calcular à força bruta. Isto irá certamente ter um impacto em como os computadores de xadrez irão evolver no futuro, e nós talvez tenhamos de aceitar com relutância que o xadrez mais perspicaz é jogado por máquinas.
O equipamento que o AlphaZero utiliza não estará acessível ao público que joga xadrez no futuro próximo, mas não te esqueças que quando o Deep Thought que foi construído personalizadamente (o predecessor do Deep Blue) bateu Bent Larsen em 1988, os seus criadores não poderiam ter imaginado que crianças e adolescentes iriam futuramente ter consigo aquele tipo de poder computacional nos seus bolsos.
Presta atenção a este espaço, como eles dizem.
Gostarias de receber mais conteúdo de xadrez em Português? Segue estes canais!
| /chesscom.pt | /chesscom_pt | /chesscomPT | /chesscom_xadrez |
