
Как устроен шахматный мозг AlphaZero?
В первой части статьи я рассказывал, как AlphaZero считает варианты. В этой части я остановлюсь на том, как она обучается игре в шахматы.
Мне придется пропустить некоторые детали, но надеюсь, что открою достаточно, чтобы вы лучше поняли, как работает AlphaZero.
Как устроена AlphaZero
Давайте перейдем к самой сути: AlphaZero обучается с использованием нейросети, которую можно изобразить следующим образом:
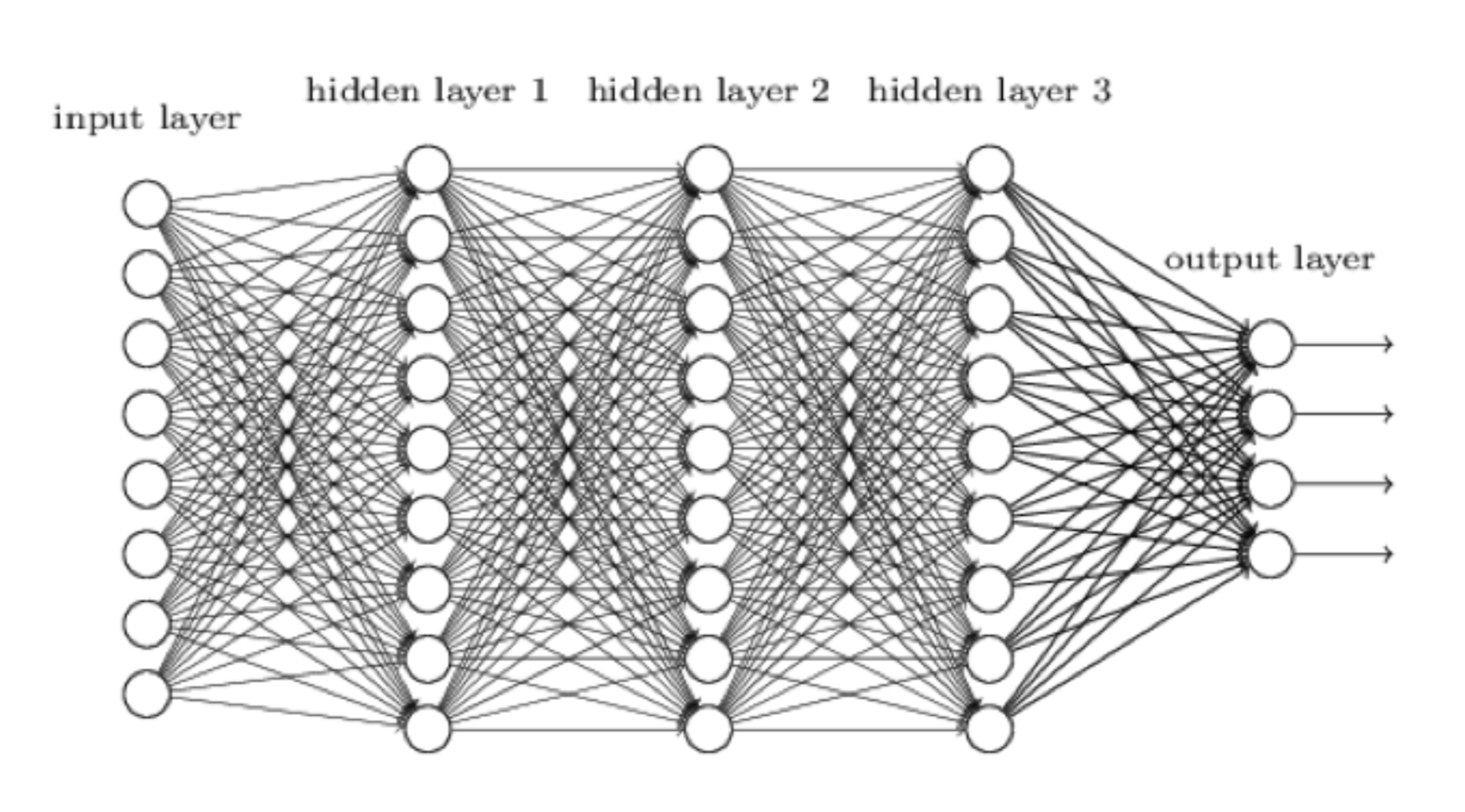 Нейросеть - попытка сделать компьютерную систему более похожей на человеческий мозг, а не, сами понимаете, кремниевый. Данные на входе, то есть, позиция на доске, приходят слева. Их обрабатывает первый слой нейронов, каждый из которых передает данные на выходе нейронам следующего слоя, и так далее, пока мы не получим конечные данные от самого правого слоя нейронов. В AlphaZero конечные данные состоят из двух частей:
Нейросеть - попытка сделать компьютерную систему более похожей на человеческий мозг, а не, сами понимаете, кремниевый. Данные на входе, то есть, позиция на доске, приходят слева. Их обрабатывает первый слой нейронов, каждый из которых передает данные на выходе нейронам следующего слоя, и так далее, пока мы не получим конечные данные от самого правого слоя нейронов. В AlphaZero конечные данные состоят из двух частей:
- Оценка данной шахматной позиции.
- Оценка каждого возможного хода в этой позиции.
Да, AlphaZero уже похожа на шахматиста: “У белых небольшой перевес, и ходы Сg5 и h4 смотрятся неплохо!”

Что такое нейроны? Нейрон - узел нейронной сети (существующий в виде оборудования или программного обеспечения) получающий данные на входе, умножающий их на определенные весы, суммирующий результаты и применяющий так называемую функцию активации, которая выдает итоговую оценку, обычно от 0 до 1. Нужно отметить, что итоговый результат зависит от каждого нейрона в сети, что позволяет улавливать тонкости. Например, рокированный белый король расположен безопасно, но после h3 оценка меняется, потому что черные могут открыть вертикаль "g" посредством g7-g5-g4.
На основании опубликованных сведений о AlphaGo Zero (программе-предшественнице AlphaZero, играющей в Го) в нейросети AlphaZero примерно 80 уровней и сотни тысяч нейронов. Подсчитайте и вы поймете, что это - сотни миллионов весов. Весы важны, потому что тренировка сети (также называемая обучением) состоит в изменении весов, позволяющем сети лучше играть в шахматы. Представьте, что существует нейрон, во время обучения оценивающий, насколько безопасно расположен король. Он получает на входе данные от всех предшествующих нейронов сети и узнает, какие весы им присвоить. Если AlphaZero получит мат, сходив всеми пешками, расположенными перед королем, ее весы изменятся, чтобы избежать повторения этой ошибки.
Как учится AlphaZero
AlphaZero начинает с нуля - большой нейронной сети со случайными весами. Она создана, чтобы обучаться играм с двумя противниками, делающими ходы по очереди, но ничего не знает о каждой отдельной игре. Так люди рождаются с хорошими способностями к изучению языков, но без знания какого-то определенного языка.
Первый шаг - научить AlphaZero правилам шахмат, чтобы она могла делать хоть и случайные, но допустимые ходы. На следующем этапе человек учился бы по партиям мастеров, этот подход называется "обучение с учителем". В случае AlphaZero это привело бы только к тому, что программа узнала бы, как играют в шахматы люди со всеми их недостатками, поэтому разработчики Google использовали более амбициозный подход, называемый "обучение с подкреплением". Это значит, что AlphaZero стала играть миллионы партий сама с собой. После каждой партии она корректировала весовые критерии, пытаясь закодировать (то есть, запомнить), что принесло пользу, а что - нет.
В начале процесса обучения AlphaZero делала случайные ходы и знала только то, что цель партии - поставить мат. Представьте, как сложно учиться контролировать центр или вести атаку пешечного меньшинства, всего лишь зная, кто получил мат в конце партии! В ходе обучения успехи AlphaZero оценивались с помощью турниров по одной секунде на ход против собственных более ранних версий и программы Stockfish. Кажется невероятным, но после четырех часов игры с собой AlphaZero узнала о шахматах достаточно, чтобы превзойти Stockfish, оценивая в ходе партии всего примерно 0.1 процента позиций, оцениваемых Stockfish.
Это потрясает, но вспомним, что и человечество училось играть в шахматы сходным образом. Сотнями лет миллионы людей играли в шахматы, используя свой мозг, чтобы узнать больше об этой игре, как гигантский многопроцессорный органический компьютер. Мы тоже прошли тернистый путь, прежде чем научились строить игру через центр, ставить ладьи на открытые вертикали, атаковать базу пешечной цепи и тому подобному. Все это пришлось узнать и AlphaZero. Было бы интересно изучить 44 миллиона партий, которые она сыграла сама с собой. Любопытно, как была открыта атака пешечного меньшинства?
Как AlphaZero играет в шахматы
Мы уже узнали, как AlphaZero тренирует свою нейронную сеть, чтобы оценивать позицию на доске и предполагать, какие ходы, скорее всего, окажутся хорошими (ничего не считая).
Добавим новые термины: часть нейросети, оценивающая позиции, называется "оценочной сетью", а та часть, которая подсказывает ходы, "стратегической сетью". Посмотрим, как эти сети помогают AlphaZero играть в шахматы.
Вспомним, что проблемой шахмат является взрывное ветвление вариантов. Расчет на два хода вперед из дебютной позиции требует оценки 150,000 позиций и с увеличением глубины это количество растет экспоненциально. AlphaZero сокращает количество вариантов, рассматривая только ходы, рекомендованные ее стратегической сетью. Она также использует оценочную сеть, чтобы прекратить изучение вариантов с ясной оценкой (победа/поражение).
Допустим, что стратегическая сеть предлагает в среднем по три заслуживающих внимания хода в каждой позиции. При скорости 80,000 позиций в секунду, которую использует AlphaZero, за минуту она заглянет на семь полных ходов вперед. Добавьте к этому инстинктивную оценку позиций, возникающих в конце вариантов, с помощью оценочной сети и вы получите очень мощную машину для игры в шахматы.
На каком оборудовании работает AlphaZero
Неудивительно, что нейронная сеть AlphaZero работает на специальном оборудовании, тензорных процессорах Google (TPU). AlphaZero использовала 5,000 TPU первого поколения чтобы играть с собой тренировочные партии и 64 TPU второго поколения для обучения как такового. Это огромные вычислительные мощности. Для игры в шахматы против Stockfich использовались всего четыре тензорных процессора.
Почему Google не использовал остальные 5,060 процессоров? Возможно, чтобы показать, что для эффективной работы AlphaZero не нужно гигантских вычислительных мощностей.

Тензорные процессоры Google (TPU).
Когда оценки передаются по сети от уровня к уровню, каждый показатель на входе каждого нейрона умножается на определенный вес - это матричное умножение (вы помните со школы, как это делается?). Тензорный процессор был разработан Google именно для обучения нейронных сетей, поэтому он специализируется на матричном умножении, которое потребовало бы от обычного процессора в вашем компьютере долгой серии вычислений. Тензорный процессор выполняет матричное умножение за один тактовый цикл (а TPU первого поколения работает со скоростью 700 миллионов циклов в секунду). Это можно сравнить с машиной на фабрике, которая закрывает крышками сразу по 100 бутылок лимонада, и каким-нибудь бедолагой, закручивающим их по одной.
AlphaZero против Stockfish
После четырех часов обучения рейтинг AlphaZero превзошел рейтинг Stockfish. Она тренировалась еще четыре часа, но за это время добилась очень малого, практически неощутимого прогресса. Это само по себе интересно, но создатели не предоставили дополнительной информации, которая позволяла бы делать выводы). После этого программы сыграли матч из 100 партий с контролем времени одна минута на ход, который AlphaZero выиграла со счетом 64-36 без поражений. Счет кажется разгромным, но соответствует разнице всего в 100 очков рейтинга Эло. Об условиях матча говорилось разное. Stockfish играл без дебютной книги, обычной для матчей компьютеров. Stockfish использовал 64 потока, работая на очень мощном компьютере, но размер хэша составлял всего 1 GB. Для обучения AlphaZero применялись 5,064 TPU, но в матче всего четыре.
Поступало много предложений о том, как сделать стартовые условия для программ справедливыми, но это невозможно, потому что они используют совершенно разное оборудование. Гонка человека с лошадью не стала бы справедливой, если бы она бежала всего на двух ногах.
Несомненно и удивительно, что сочетание вычислительных мощностей и программных алгоритмов AlphaZero позволило этой программе научиться за четыре часа оценивать позиции и ходы лучше, чем постоянно совершенствуемый Stockfish.
Если вы все еще киваете на размер хэша Stockfish, вы упускаете истинный смысл случившегося. Подумайте: достижение AlphaZero было бы лишь чуть менее удивительным, если бы эта программа проиграла Stockfish с тем же счетом.
Хочу запустить AlphaZero на своем ноуте!
Нужно кое-что уточнить! AlphaZero обучает нейросеть. И вам нужна именно нейросеть, обученная AlphaZero играть в шахматы. Чтобы выправить вывихнутый палец, вы идете к врачу, а не поступаете в медицинский университет. Разумеется, эта нейросеть была сохранена, когда обучившие ее тензорные процессоры переключились на другие задачи. Если бы структура и весы нейросети были опубликованы, стало бы возможным, по крайней мере, теоретически, воспроизвести работу AlphaZero на ноутбуке, но ее сила отличалась бы от того, что можно достичь на специализированном оборудовании Google.
Насколько сильно? Давайте произведем весьма грубые подсчеты. Деталь вашего компьютера, лучше всего подходящая для расчетов, которые выполняет AlphaZero - видеокарта. Это вовсе не странно, ведь умножение матриц требуется в графике не меньше, чем в нейросетях. Google считает, что его тензорные процессоры примерно в 20 раз быстрее современных видеокарт, так что машина из четырех тензорных процессоров, победившая Stockfish, в 80 раз более производительна, чем обычный персональный компьютер. На сегодня это превосходит возможности обычного пользователя.
Революция совершается в области искусственного интеллекта, где нейронные сети используются для решения проблем, раньше считавшихся слишком сложными для компьютеризации. AlphaZero - многоцелевая программа, благодаря этому она научилась понимать шахматы (а не просто считать варианты) намного лучше, чем это удалось бы специальному шахматному алгоритму. Кстати, она также освоила го и сёги, настольные игры, где труднее считать варианты, чем в шахматах. Непохоже, что Google заинтересован в дальнейшем развитии шахматного проекта — эта компания ставит перед собой более амбициозные и полезные задачи.
Что это значит для нашего шахматного мира? Совершен гигантский шаг: компьютер может освоить шахматную игру на высоком уровне, полагаясь на обучение, присущее людям, а не на привычный для компьютеров счет методом полного перебора. Это способно поколебать наше представление о человеческом превосходстве и неизбежно повлияет на развитие шахматных движков в будущем, поскольку нам придется неохотно согласиться, что машины не только лучше считают варианты, но и лучше понимают шахматы.
Оборудование, на котором работает AlphaZero, еще не скоро станет доступно любителям шахмат, но не забывайте, что в 1988 году, когда специальный компьютер Deep Thought (предшественник Deep Blue) выиграл партию у Бента Ларсена, его создатели не могли вообразить, что в будущем дети станут носить столь же мощные вычислительные устройства в своих карманах.
Следите за новостями, как говорится.

