
What's Inside AlphaZero's Chess Brain?
In the first part of this article I described how AlphaZero calculates variations. In this part I’ll cover how it learns, by itself, to play chess.
I’ll have to gloss over some details, but hopefully there’s enough to give you a better understanding of how AlphaZero works.
Inside AlphaZero
Let’s jump right in to the middle of this. AlphaZero’s learning happens using a neural network, which can be visualized like this:
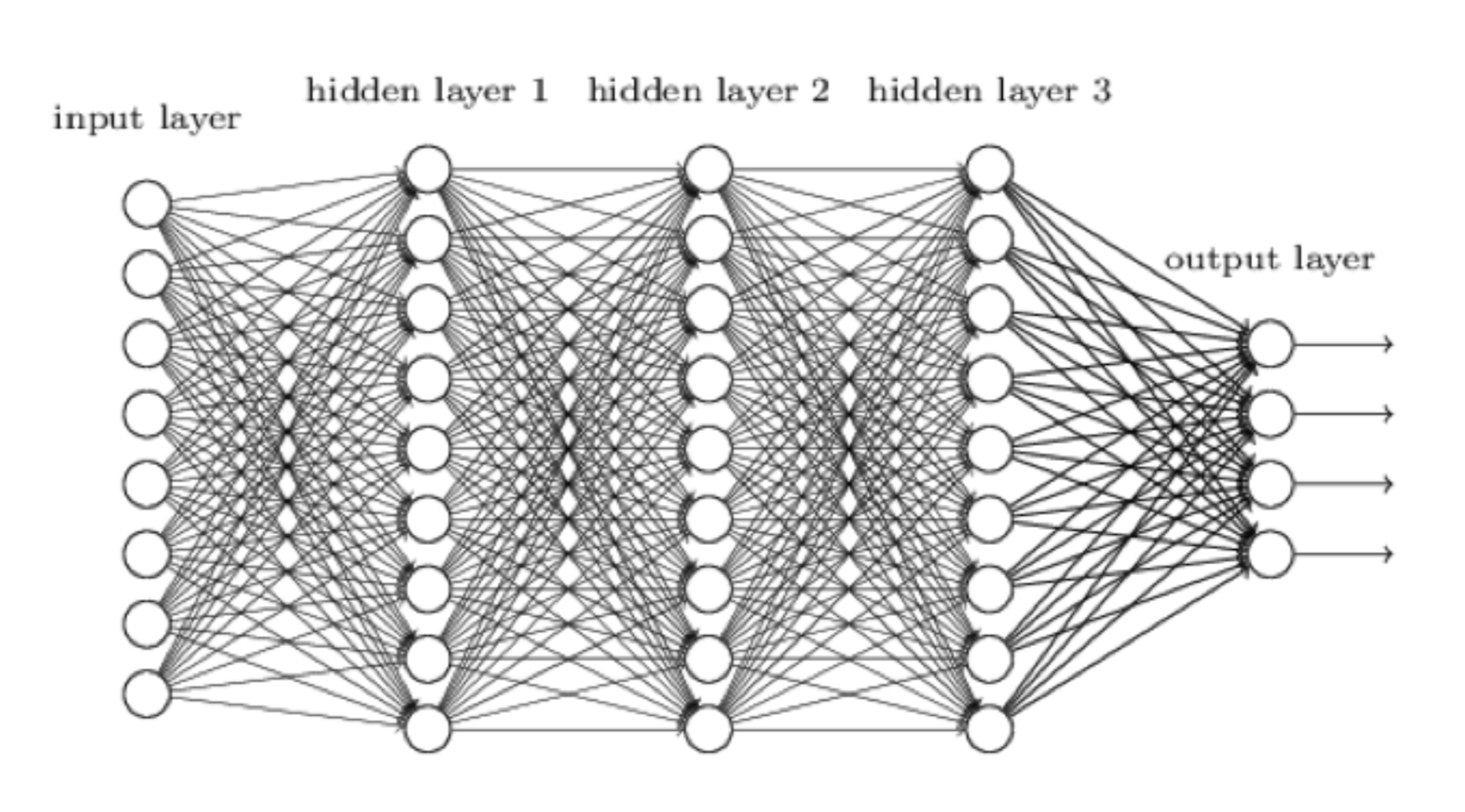 A neural network is our attempt at making a computer system more like the human brain and less like, well, a computer. The input, i.e., the current position on the chessboard, comes in on the left. It gets processed by the first layer of neurons, each of which then sends its output to each neuron in the next layer and so on, until the rightmost layer of neurons do their thing and produce the final output. In AlphaZero, this output has two parts:
A neural network is our attempt at making a computer system more like the human brain and less like, well, a computer. The input, i.e., the current position on the chessboard, comes in on the left. It gets processed by the first layer of neurons, each of which then sends its output to each neuron in the next layer and so on, until the rightmost layer of neurons do their thing and produce the final output. In AlphaZero, this output has two parts:
- An evaluation of the chess position it was given.
- An evaluation of each legal move in the position.
Hey, AlphaZero sounds like a chess player already: “White’s a bit better here, and Bg5 or h4 look like good moves!”

So these neurons must be smart little devils, right? A neuron is actually a very simple processing unit (it can be in software or hardware) that accepts a number of inputs, multiplies each one by a particular weight, sums the answers and then applies a so-called activation function that gives an output, typically in the range of 0 to 1. One thing to notice is that what a neuron outputs potentially depends on every other neuron in the network before it, which allows the network to capture subtleties, like in chess where White’s castled king is safe, but after h3 the assessment changes as Black can open the g-file with g7-g5-g4.
Based on the data published for AlphaGo Zero (AlphaZero’s Go-playing predecessor) AlphaZero’s neural network probably has up to 80 layers, and hundreds of thousands of neurons. Do the math and realize that this means hundreds of millions of weights. Weights are important because training the network (also called learning) is a matter of giving the weights values so that the network plays chess well. Imagine there’s a neuron that during training has taken on the role of assessing king safety. It takes input from all preceding neurons in the network and learns what weights to give them. If AlphaZero gets mated after moving all its pawns in front of its king, it will adjust its weights to reduce the possibility of making this error again.
How AlphaZero Learns
AlphaZero starts out as a blank slate, a big neural network with random weights. It has been engineered to learn how to play two-player, alternate-move games, but knows absolutely nothing about any particular game at all, much as we are born with a vast capacity to learn language, but with no knowledge of any particular language.
The first step was to give AlphaZero the rules of chess. This meant it can now play random, but at least legal, moves. The natural next step would seem to be to give it master games to learn from, a technique called supervised learning. However this would have resulted in AlphaZero only learning how we play chess, with all its flaws, so the Google team chose instead to use a more ambitious approach called reinforcement learning. This means that AlphaZero was left to play millions of games against itself. After each game it would tweak some of its weights to try to encode (i.e., remember) what worked well and what didn’t.
When it started this learning process, AlphaZero could only play random moves and all it knew was that checkmate is the goal of the game. Imagine trying to learn principles like central control or the minority attack, simply from who checkmated whom at the end of the game! During this learning period, AlphaZero’s progress was measured by playing second-a-move tournaments with Stockfish, and the previous versions of itself. It seems utterly incredible, but AlphaZero after four hours of self-play had learned enough about chess to exceed Stockfish’s rating, while examining only about 0.1 percent of the number of positions Stockfish examined.
While this is pretty mind-blowing, remember humankind learned chess in a similar way. For centuries, millions of humans have being playing chess, using our brains to learn more about this game, like a giant multi-processor carbon-based computer. We learned the hard way to play in the center, put rooks on open files, attack pawn chains at the base, etc.. This is what AlphaZero had to do too. It would be fascinating to see its 44 million games of self-play. I wonder in which one did it discover the minority attack?
How AlphaZero Plays Chess
So far we’ve seen how AlphaZero trains its neural network so it can evaluate a given chess position and assess which moves are likely to be good (without calculating anything).
Here’s some more terminology: the part of the network that evaluates positions is called the value network, while the "move recommender" part is called the policy network. Now let’s see how these networks help AlphaZero in actually playing chess.
Recall that the big problem in chess is the explosion of variations. Just to calculate two moves ahead from the opening position involves looking at about 150,000 positions, and this number grows exponentially for every move deeper you go. AlphaZero reduces the number of variations to look at by only considering those moves that its policy network recommends. It also uses its value network to stop looking further down lines whose evaluation suggests that they are clearly decided (won/lost).
Say there’s an average of three decent possible moves available, according to the policy network. Then at the very modest rate of 80,000 positions per second employed by AlphaZero, it could look about seven full moves ahead in a minute. Couple this with applying its instinctual evaluation provided by its value network to the leaf positions at the end of the variations it looks at, and you have a very powerful chess-playing machine indeed.
The Hardware AlphaZero Runs On
Unsurprisingly the AlphaZero’s neural network runs on specialist hardware, namely Google’s tensor processing units (TPU). AlphaZero uses 5,000 first-generation TPUs to generate the self-play games, which are used to train the network, and 64 second-generation TPUs to do the actual training. This is a gigantic amount of computing power. For actually playing chess, only four TPUs were used.
Why didn’t Google use the other 5,060 TPUs as well? Probably to show that AlphaZero doesn’t need massive hardware to run effectively.

Google’s tensor processing units (TPU).
As a neural network propagates values between its layers, each input to each neuron is multiplied by a certain weight, in what is essentially matrix multiplication (remember that from school?). The TPU was designed by Google purely for training and running neural networks, and so it specializes in doing matrix multiplication. A matrix multiplication operation that would take a regular CPU in your laptop a long series of calculations, a TPU can do in a single clock cycle (and the first generation TPU does 700 million cycles per second). Think of a machine in a factory that can put caps on 100 bottles of soda at once, vs some poor soul putting them on one-by-one.
AlphaZero vs Stockfish
After four hours training, AlphaZero’s rating had exceeded that of Stockfish. It trained for five more hours, but made little or no improvement in this time (yes, this is interesting in itself, but the researchers didn’t provide more information to enable an interpretation). At this point the two played a 100-game match, one minute a move, which AlphaZero won with 64-36 with no losses. This seems like a hammering, but in fact corresponds to only a 100-point difference in Elo rating. Much has been made of the fairness or otherwise of this match. Stockfish was denied its opening book, which is typical of computer matches. Stockfish used 64 threads, which suggests it was running on a very powerful PC, but only used a modest hash size of 1 GB. As against that, AlphaZero had 5,064 TPUs at its disposal, but only used four of them in the match.
Many people have proposed how to make a fair match between the two, but this is not really possible, as they rely on radically different hardware. A race between a person and a horse would not be made “fair” by only permitting the use of two legs.
What is undeniable, and amazing, is that AlphaZero’s combination of hardware and software could learn, in four hours, how to evaluate chess positions and moves better than the highly-refined Stockfish.
If you’re still thinking about the size of Stockfish’s hash table, you’re really missing the point of what’s happened. Put it this way: AlphaZero’s achievement would have been only a shade less amazing had it instead lost to Stockfish by a similar score.
I Want AlphaZero On My Laptop!
Oh no you don’t! AlphaZero trains neural networks. What you want is the neural network that AlphaZero trained to play chess. The same way you want a doctor to look at your swollen finger, not a medical university. No doubt this neural network was dumped to disk while the TPUs that trained it were assigned other duties. If the network structure and weights were published, it would, in theory at least, be possible to recreate AlphaZero’s chess-playing network on a laptop, but its performance would not be up to what can be achieved with Google’s specialist hardware.
How close would it come? Let’s do some very rough sums. The part of your computer that is best-suited to the calculations that AlphaZero performs is the GPU or graphics processing unit. The may seem odd, but graphics are all about matrix multiplication, which is just what a neural network needs too. Google estimates its TPU to be about 20 times faster than a contemporary GPU, so the the 4-TPU machine that defeated Stockfish is relying on about 80 times more oomph than a regular PC. So for the moment, this will be beyond the home user.
A revolution is taking place in the artificial intelligence field, where neural networks are being used to tackle problems that were previously seen as too complex for a computational approach. AlphaZero’s general-purpose approach enabled it to teach itself to understand chess (not just calculate variations) far better than any chess-specific approach has been able to. Oh, and it did this for Go and Shogi as well, board games with higher computational complexity than chess. It’s very unlikely that Google will be interested in progressing the chess project any further—it will be setting its sights on more challenging and worthwhile problems.
So what does this all mean for chess as we know it? It is a gigantic step that a computer can now teach itself chess to such a high level, relying more on human-like learning than on traditional, brute-force calculation. This creates a dent in our notion of human supremacy. It will undoubtedly have an impact on how chess engines will evolve in the future, and we may have to accept reluctantly that the most insightful chess is played by machines.
The hardware AlphaZero runs on won’t be available to the chess-playing public anytime soon, but don’t forget that when the custom-built Deep Thought (predecessor to Deep Blue) beat Bent Larsen in 1988, its creators hardly imagined that future school kids would carry that kind of computing power in their pocket.
Watch this space, as they say.





