
Co znajduje się wewnątrz szachowego mózgu AlphaZero?
W pierwszej części tego artykułu opisałem w jaki sposób AlphaZero liczy warianty. W tej części natomiast, wytłumaczę jak sam siebie uczy grać w szachy.
Będę musiał pominąć niektóre szczegóły, ale mam nadzieję, że w wystarczającym stopniu przybliżę Ci sposób działania AlphaZero.
Wewnątrz AlphaZero
Wskoczmy od razu na głęboką wodę. Uczenie się AlphaZero ma miejsce przy użyciu sieci neuronowej, która może być zwizualizowana w ten sposób:
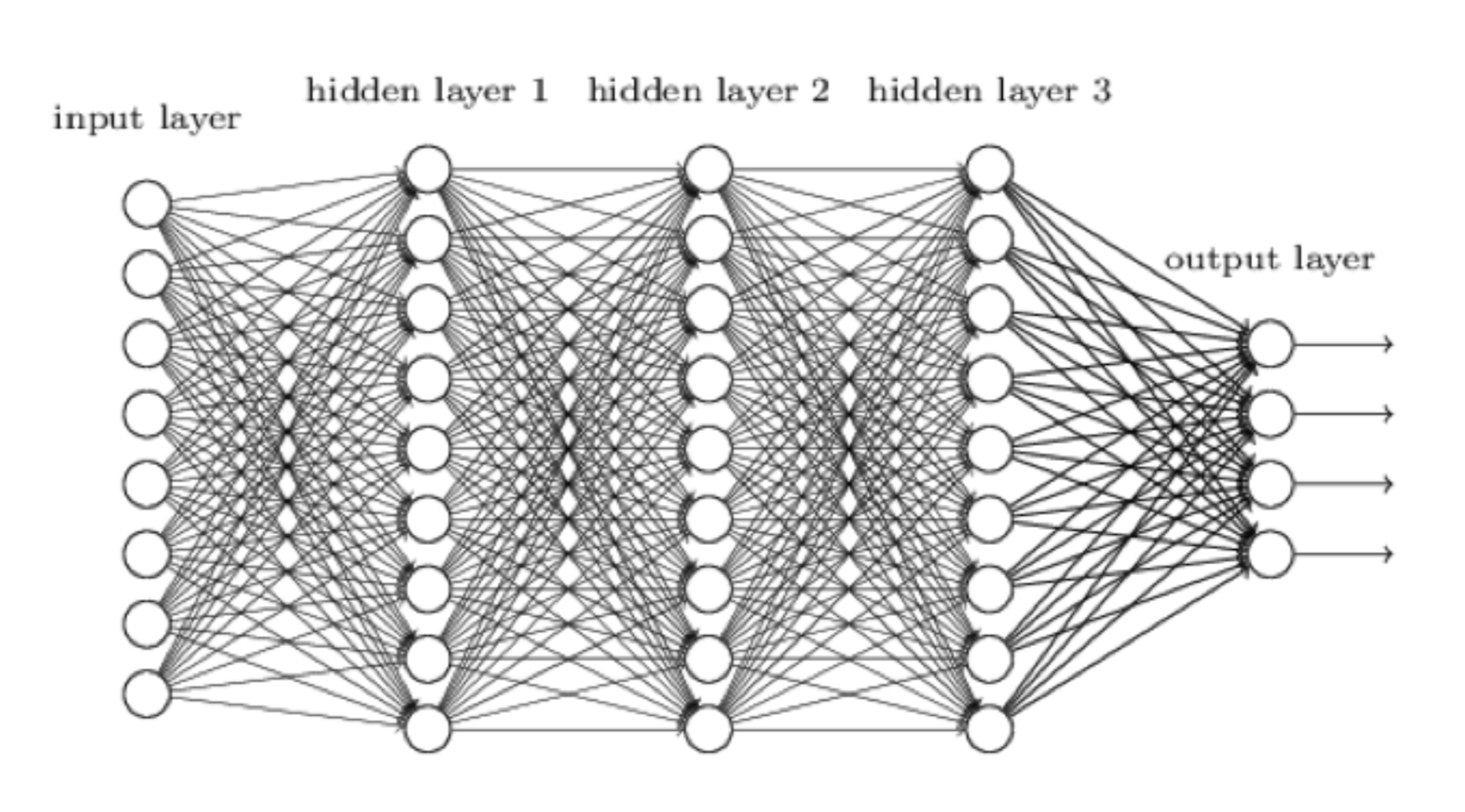 Sieć neuronowa jest naszą próbą stworzenia systemu komputerowego, który będzie działał bardziej jak umysł człowieka, a mniej jak komputer. Dane wejściowe, tj. bieżąca pozycja na szachownicy, plasuje się po lewej stronie. Ulega przetworzeniu przez pierwszą warstwę neuronów, następnie każde z nich przesyła swoje wyjście do każdego neuronu w następnej warstwie i tak dalej, do momentu kiedy najbardziej wysunięta na prawo warstwa neuronów spełni swoje zadanie i wyprodukuje końcowe dane wyjściowe. W AlphaZero, składają się one z dwóch części:
Sieć neuronowa jest naszą próbą stworzenia systemu komputerowego, który będzie działał bardziej jak umysł człowieka, a mniej jak komputer. Dane wejściowe, tj. bieżąca pozycja na szachownicy, plasuje się po lewej stronie. Ulega przetworzeniu przez pierwszą warstwę neuronów, następnie każde z nich przesyła swoje wyjście do każdego neuronu w następnej warstwie i tak dalej, do momentu kiedy najbardziej wysunięta na prawo warstwa neuronów spełni swoje zadanie i wyprodukuje końcowe dane wyjściowe. W AlphaZero, składają się one z dwóch części:
- Oceny pozycji, którą silnik otrzymał.
- Sprawdzeniu każdego dozwolonego ruchu w pozycji.
Hej, AlphaZero już brzmi jak zawodnik szachowy: "Białe są tutaj trochę lepsze, a Gg5 albo h4 wyglądają na dobre posunięcia!"

Czyli, neurony to takie małe diabełki, tak? W rzeczywistości neuron to bardzo prosta jednostka przetwarzająca (może znajdować się w oprogramowaniu lub sprzęcie komputerowym), która akceptuje duże ilości danych wejściowych, rozmnaża je, podlicza odpowiedzi i wówczas wprowadza tak zwaną funkcję aktywacji, która daje dane wyjściowe, najczęściej w zakresie od 0 do 1. Warto zwrócić uwagę na to, że to co wytwarza neuron potencjalnie zależy od każdego innego neuronu w sieci znajdującego się przed nim, co z kolei pozwala sieci na wychwytywanie niuansów. Jak na przykład bezpieczeństwo zroszowanego białego króla, ale po ruchu h3, ocena ulega zmianie, gdyż Czarne mogą otworzyć linię g za pomocą ruchów g7-g5-g4.
W oparciu o dane opublikowane na temat AlphaGo Zero, sieć neuronowa Alphy Zero prawdopodobnie posiada około 80 warstw i setki tysięcy neuronów. Po podliczeniu można zdać sobie sprawę, że to setki milionów wag. Wagi są ważne, ponieważ trenowanie sieci (nazywane również uczeniem) jest kwestią nadania wagom wartości, co pozwala sieci grać dobrze w szachy. Wyobraź sobie, że w czasie treningu pewien neuron podjął się zadaniu oceny bezpieczeństwa króla. Pobiera on wówczas dane wejściowe wszystkich poprzednich neuronów w sieci i dowiaduje się jakie wagi im dać. Jeśli AlphaZero dostanie mata po zrobieniu ruchów wszystkimi swoimi pionkami sprzed króla, dostosuje swoje wagi tak, aby zredukować ewentualność popełnienia tego samego błędu.
Jak AlphaZero się uczy
AlphaZero rozpoczyna jako pusta tabliczka, wielka sieć neuronowa z przypadkowymi wagami. Silnik ten został skonstruowany tak, aby nauczył się dwuosobowej gry, partii z naprzemiennymi ruchami, natomiast absolutnie nie wie nic o żadnej konkretnej grze. Przypomina to sytuację, gdy rodzimy się, posiadając rozległą zdolność nauki języka, a nie mamy na jego temat żadnej wiedzy.
Pierwszym krokiem było wpojenie AlphaZero zasad gry w szachy. Oznaczało to, że silnik może wykonywać zupełnie przypadkowe posunięcia, ale przynajmniej bedą one dozwolone. Następnym, naturalnym krokiem byłoby więc, pokazanie maszynie partii mistrzów szachowych, tak aby mogła się z nich uczyć. Taka technika nazywana jest nadzorowaną nauką. Jednakże, skutkowałoby to tym, że AlphaZero uczy się tego, jak my gramy w szachy wraz z wszystkimi popełnianymi przez ludzi pomyłkami. Tak więc, zespół Google obrał bardziej ambitne podejście do sprawy, zwane wzmocnioną nauką. Znaczyło to, że AlphaZero miał rozegrać miliony partii przeciwko sobie. Po każdej partii silnik ulepszał niektóre ze swoich wag, by spróbować zakodować (zapamiętać) co wyszło dobrze, a co nie.
Kiedy rozpoczął się proces nauki, Alpha Zero mógł grać tylko przypadkowe ruchy i jedyne co wiedział, to to, że celem partii jest danie mata. Wyobraź sobie sytuację, w której uczysz się zasad takich jak kontrola centrum lub atak mniejszościowy w oparciu o to, kto kogo w rezultacie zamatował! W czasie okresu nauki, progres AlphaZero był sprawdzany poprzez rozgrywanie turniejów ze Stockfishem (oraz jego poprzednimi wersjami), w których czas na posunięcie wynosił jedną sekundę. Wydaje się to całkowicie niesamowite, ale AlphaZero po czterech godzinach grania przeciwko sobie, nauczył się wystarczająco dużo o szachach, aby przewyższyć ranking Stockfisha, pomimo faktu, że przeanalizował jedyne 0,1 procenta pozycji, które przeanalizował Stockfish.
Jest to fantastyczne, ale pamiętaj, że ludzkość nauczyła się gry w szachy w podobny sposób. Przez wieki, miliony ludzi grało w szachy używając swoich mózgów, by nauczyć się o tej grze jak najwięcej, tak jak olbrzymi, wieloprocesowy komputer. Nauczyliśmy się na własnych błędach, żeby grać w centrum, stawiać wieże na otwartych liniach, atakować podstawę łańcucha pionkowego i tak dalej. AlphaZero musiał robić to samo. Niesamowicie byłoby zobaczyć 44 miliony partii, które silnik zagrał przeciwko sobie. Zastanawiam się, w której z nich odkrył atak mniejszościowy?
Jak AlphaZero gra w szachy
Póki co poznaliśmy sposób w jaki AlphaZero trenuje swoją sieć neuronową, tak że potrafi policzyć zadaną mu pozycję oraz ocenić który ruch będzie prawdopodobnie dobry (bez liczenia czegokolwiek).
Oto więcej terminologii: część sieci odpowiedzialna za liczenie pozycji nazywana jest siecią wartości, natomiast część, która "zaleca posunięcia" to sieć planowania. Teraz przekonajmy się, jak właściwie te sieci pomagają AlphaZero grać w szachy.
Przypomnij sobie o wielkim problemie, jakim jest w szachach eksplozja wariantów. Policzenie dwóch ruchów do przodu z wyjściowej pozycji wiążę się z przeanalizowaniem okołu 150,000 pozycji, a liczba ta rośnie w miarę wykonywania kolejnych posunięć. AlphaZero redukuje tę ilość wariantów, rozważając tylko te, które narzuci mu sieć planowania. Silnik korzysta również ze swojej sieci wartości, w celu zaprzestania analizy dalszych opcji, których ocena jest przesądzona (wygrana/przegrana).
Powiedzmy, że średnio dostępne są trzy przyzwoite możliwości ruchów, w oparciu o sieć planowania. Wówczas, w bardzo skromnej ilości 80,000 pozycji na sekundę, AlphaZero może zobaczyć siedem ruchów do przodu w minutę. Połączmy to z zastosowaniem jego instynktownej oceny zapewnianej przez sieć wartości do krytycznych pozycji na końcu wariantów i rzeczywiście mamy do czynienia z bardzo potężną szachową maszyną.
Sprzęt, na którym pracuje AlphaZero
Jak można było się spodziewać, sieć neuronowa AlphaZero pracuje na specjalistycznym oprzyrządowaniu, a mianowicie na tensorycznych jednostkach przetwórczych firmy Google (TPU). Maszyna ta, używa 5,000 TPU pierwszej generacji, aby wygenerować partie, które AlphaZero gra przeciwko sobie, a te z kolei są niezbędne do trenowania sieci; 64 TPU drugiej generacji stosowane są do przeprowadzenia właściwego treningu. Jest to gigantyczna wielkość mocy obliczeniowej. Natomiast do samego grania w szachy zostały użyte jedynie 4 TPU.
Dlaczego Google nie użył również pozostałych 5,060 TPU? Prawdopodobnie po to, aby pokazać, że AlphaZero nie potrzebuje masywnego sprzętu komputerowego, żeby działać efektywnie.

tensoryczne jednostki przetwórcze firmy Google (TPU).
W czasie kiedy sieć neuronowa rozprzestrzenia wartości między swoimi warstwami, każda wejście do każdego neuronu jest mnożone przez pewną wagę, co w rzeczywistości jest mnożeniem macierzy (pamiętasz to ze szkoły?). TPU zostało stworzone przez Google wyłącznie do treningu oraz prowadzenia sieci neuronowych, tak więc specjalizuje się w mnożeniu macierzy. Operacja mnożenia macierzy przez procesor w Twoim komputerze pochłonęłaby szereg długich kalkulacji, natomiast TPU może to zrobić w czasie pojedynczego cyklu zegara (TPU pierwszej generacji robi 700 milionów cyklów na sekundę). Wyobraź sobie maszynę w fabryce, która potrafi nałożyć kapsle na 100 butelek jednocześnie i porównaj z biednym człowiekiem nakładającym je jeden po drugim.
AlphaZero vs Stockfish
Po czterech godzinach treningu, ranking AlphaZero przewyższył ranking Stockfisha. Silnik trenował jeszcze przez kolejne pięć godzin, ale nie zrobił wielkiego postępu w tym czasie (jest to interesujące, aczkolwiek pracownicy naukowi nie dostarczyli żadnych informacji, które umożliwiłyby tego interpretację). W tym miejscu, dwie maszyny rozegrały między sobą mecz, składający się ze 100 partii, gdzie tempo gry wynosiło jedną minutę na posunięcie. AlphaZero wygrał ten mecz bez żadnych przegranych, 64 do 36. Wygląda to na totalne rozgromienie, a w rzeczywistości odpowiada tylko 100 punktowej różnicy rankingowej. Wiele dyskutowano na temat uczciwości tego meczu. Stockfishowi odmówiono korzystania z jego książki debiutowej, co jest z kolei typowe dla meczów komputerowych. Ponadto, silnik użył 64 wątków, co sugeruje, że działał na bardzo potężnym komputerze, korzystając ze skromnego rozmiaru 1 GB. Z drugiej strony, AlphaZero miał do swojej dyspozycji 5,064 TPU, a użył jedynie cztery z nich.
Wiele ludzi sugerowało w jaki sposób przeprowadzić sprawiedliwy mecz pomiędzy dwoma silnikami, ale właściwie nie jest to możliwe, zważając na fakt, że funkcjonują one na radykalnie różnych komputerach. Wyścig pomiędzy człowiekiem a koniem również nie byłby uczciwy, jeśli dopuszczone byłoby użycie tylko dwóch nóg.
Niezaprzeczalne i niesamowite jest to, że połączenie sprzętu komputerowego i oprogramowania AlphaZero potrafiło nauczyć się, w przeciągu czterech godzin, jak oceniać pozycje i ruchy szachowe, lepiej od wybitnie dopracowanego Stockfisha.
Jeśli wciąż rozmyślasz o formacie tablicy wartości funkcji mieszającej Stockfisha, to naprawdę nie rozumiesz sedna sprawy. Ujmijmy to w ten sposób: osiągnięcie AlphaZero byłoby tylko troszeczkę mniej niesamowite, nawet jeśli przegrałby ze Stockfishem podobnym wynikiem.
Chcę AlphaZero na swoim laptopie!
Oj nie, nie chcesz! AlphaZero trenuje sieci neuronowe. To czego Ty chcesz, to sieć neuronowa, którą AlphaZero wytrenował do grania w szachy. Podobnie, jak w przypadku kiedy chcesz żeby lekarz, a nie Uniwersytet Medyczny obejrzał Twój spuchnięty palec. Nie ma wątpliwości, że ta sieć neuronowa została zrzucona na dysk, podczas gdy TPU, który ją trenował został przydzielony do innych obowiązków. Jeśli struktura sieci i wag zostałaby opublikowana, byłoby, przynajmniej w teorii, możliwe odtworzenie grającej w szachy sieci AlphaZero na laptopie, aczkolwiek jej maksymalne osiągi byłyby trudne do uzyskania bez specjalistycznego sprzętu Google.
Jak bardzo moglibyśmy się zbliżyć? Przeanalizujmy to. Część Twojego komputera, która byłaby najlepiej przystosowana do przeprowadzenia obliczeń, których dokonuje AlphaZero, to graficzna jednostka przetwórcza (GPU). Może wydawać się to dziwne, ale grafika równa się mnożenie macierzy, a tego właśnie potrzebuje sieć neuronowa. Google szacuje, że ich TPU są około 20 razy szybsze od współczesnych GPU. Oznacza to, że na ten moment, przekracza to możliwości domowego użytkownika.
Rewolucja ma miejsce w dziedzinie sztucznej inteligencji, gdzie sieci neuronowe są używane do stawiania czoła problemom, które wcześniej były uważane za zbyt złożone dla rachunkowego podejścia do sprawy. Uniwersalne podejście AlphaZero umożliwiło mu natomiast, nauczenie się zrozumienia szachów (nie tylko liczenia wariantów), dużo lepiej niż jakiekolwiek inne ukierunkowane szachowo podejście było w stanie. Aha, zrobił to też dla Go i Shogi, czyli gier o większej złożoności obliczeniowej od szachów. Nie jest prawdopodobne, by Google było zainteresowane dalszym rozwojem szachowego projektu-będą wyznaczać sobie bardziej wymagające i warte zachodu zadania.
A zatem, to wszystko oznacza dla szachów? Jest to gigantyczny krok, komputer potrafi nauczyć się jak grać w szachy na najwyższym poziomie, opierając się na tym, jak robią to ludzie, a nie na tradycyjnych, wymuszonych obliczeniach. Tworzy to uszczerbek w naszym wyobrażeniu o ludzkiej wyższości. Niewątpliwie będzie miało to wpływ na to, jak silniki szachowe bedą ewoluowały w przyszłości i być może będziemy musieli niechętnie zaakceptować fakt, że najbardziej odkrywcze szachy są grane przez maszyny.
Sprzęt, na którym pracuje AlphaZero, nie będzie udostępniony w najbliższym czasie, ale nie zapominaj, że kiedy stworzony na zamówienie Deep Thought (poprzednik Deep Blue) pokonał Benta Larsena w 1988 roku, jego twórcy nie śnili nawet o tym, że w przyszłości uczniowie szkół będą nosili taką moc obliczeniową w swoich kieszeniach.
Jak to mówią, obserwuj uważnie.