
Qu'y a-t-il dans le cerveau échiquéen d'AlphaZero ?
Dans la première partie de cet article, j'ai décrit la manière dont AlphaZero calcule les variantes. Dans cette partie, nous allons aborder la façon dont le programme a appris tout seul à jouer aux échecs.
Nous ne pourrons pas nous attarder sur tous les détails, mais j'espère que ces quelques paragraphes vous aideront à mieux comprendre la manière dont AlphaZero fonctionne !
A l'intérieur d'AlphaZero
Passons dans le vif du sujet. AlphaZero apprend grâce à un réseau neuronal, qu'on peut schématiser comme suit :
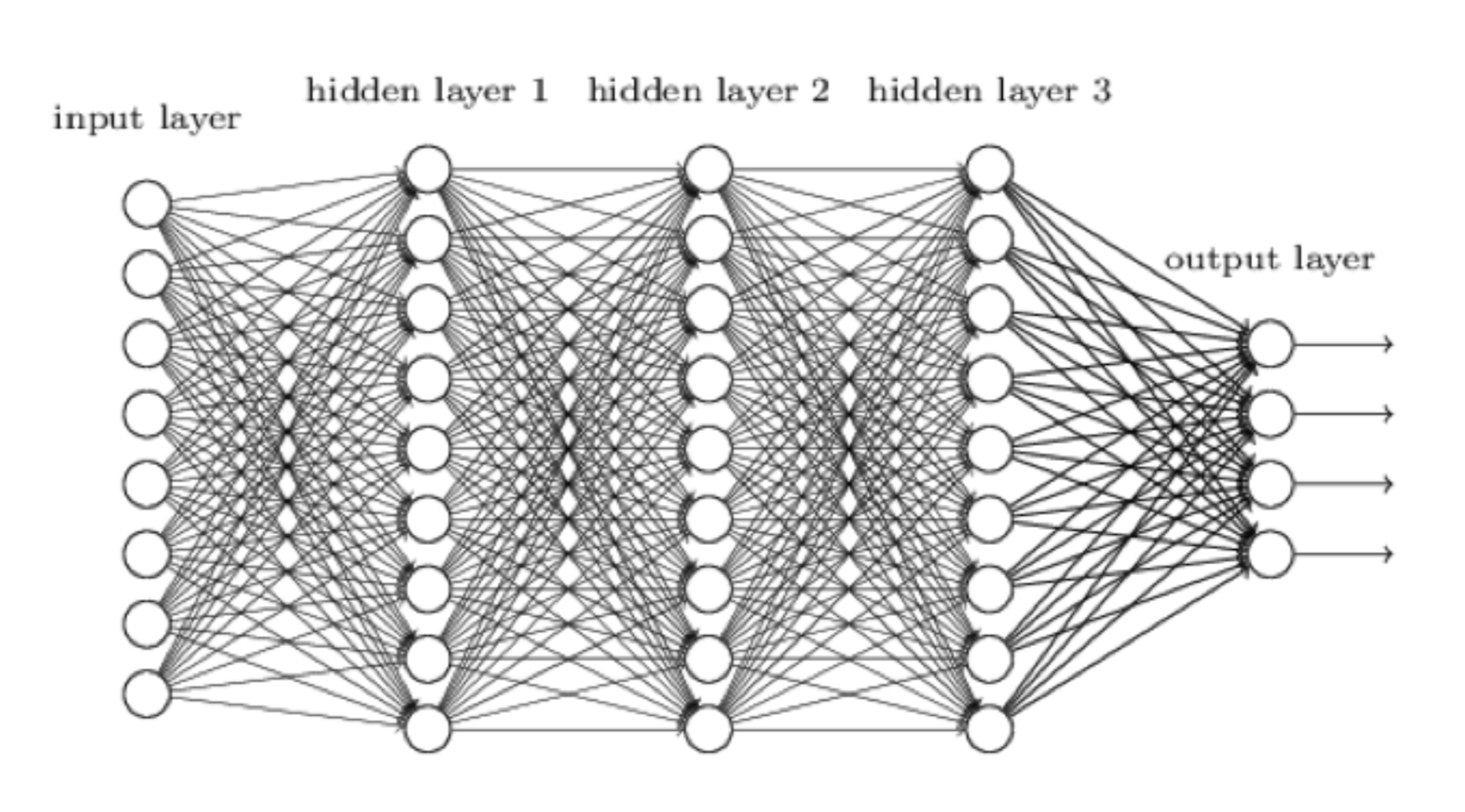
Fabriquer un réseau neuronal est la meilleure façon de tenter de répliquer le cerveau humain et de faire réfléchir la machine moins... comme une machine. Les données (par exemple, la position sur l'échiquier) arrivent par la gauche, et sont traitées par la première couche de neurones, qui envoie ses résultats à chaque neurone de la couche suivante, et ainsi de suite jusqu'à l'ultime couche, qui fourni le résultat d'analyse final. Chez AlphaZero, ce résultat se décompose en deux parties :
1. Une évaluation de la position originale.
2. Une évaluation de chaque coup légal dans la position.
AlphaZero commence donc déjà à ressembler à un vrai joueur d'échecs : "Les blancs sont un peu mieux, et Fg5 ou h4 me semble être des bons coups."
 Vous vous dites sans doute que ces neurones doivent-être des unités remarquablement intelligentes. En vérité, il s'agit d'entités très simple (matérielles ou logicielles) acceptant un nombre fixe de données, leur attribuant un poids et synthétisant leur analyse à l'aide de ce que l'on appelle une fonction d'activation. Un résumé exprimé en décimales, généralement entre 0 et 1. Il est important de remarquer que le résultat de l'analyse d'un neurone dépend potentiellement du travail des autres, ce qui permet au réseau d'appréhender toutes les subtilités de la position. Par exemple, quand le roi blanc a roqué, il est en sécurité, mais après le coup h3, l'évaluation change, car les noirs peuvent potentiellement ouvrir la colonne g par g7-g5-g4.
Vous vous dites sans doute que ces neurones doivent-être des unités remarquablement intelligentes. En vérité, il s'agit d'entités très simple (matérielles ou logicielles) acceptant un nombre fixe de données, leur attribuant un poids et synthétisant leur analyse à l'aide de ce que l'on appelle une fonction d'activation. Un résumé exprimé en décimales, généralement entre 0 et 1. Il est important de remarquer que le résultat de l'analyse d'un neurone dépend potentiellement du travail des autres, ce qui permet au réseau d'appréhender toutes les subtilités de la position. Par exemple, quand le roi blanc a roqué, il est en sécurité, mais après le coup h3, l'évaluation change, car les noirs peuvent potentiellement ouvrir la colonne g par g7-g5-g4.
Selon les données publiées sur AlphaGo (le prédécesseur d'AlphaZero, joueur de Go de son état), on peut supposer que le réseau neuronal d'AlphaZero comprend environ 80 couches, soit des centaines de milliers de neurones. Un petit calcul nous permet donc d'estimer son nombre de poids exprimés en centaines de millions. Ces poids sont importants, car la phase d'apprentissage du réseau neuronal dépend de l'évaluation des positions par le programme. Mieux il estime les positions, mieux il joue, et mieux il apprend à devenir meilleur. Imaginez qu'un neurone ait comme fonction d'évaluer la sécurité du roi. Il reçoit les données de tous les autres neurones du réseau et apprend progressivement quel poids leur attribuer. Si AlphaZero se fait mater après avoir poussé tous les pions devant le roi, il ajustera le poids affecté à chaque donnée pour éviter que cette erreur ne se reproduise.
Comment apprend AlphaZero
AlphaZero est parti d'une feuille blanche. Un gros réseau neuronal aux poids aléatoires. Comme les humains, qui naissant avec la capacité à apprendre les langues, mais sans en connaître aucune, le programme a été conçu pour jouer aux jeux à deux joueurs, mais sans rien connaître des jeux en question.
Il a donc fallut fournir les règles des échecs à AlphaZero. Cela lui a permis de jouer des coups, certes au hasard, mais légaux. L'étape suivante aurait naturellement été de lui donner des parties de maîtres à analyser. Il s'agit d'une technique appelée "apprentissage supervisé". Cependant, ce traitement aurait simplement appris à AlphaZero à jouer comme nous les faisons déjà, avec tous nos défauts humains. L'équipe de Google/Deep Mind a donc choisi une autre approche, plus ambitieuse, appelée l'apprentissage par renforcement. On a donc laissé AlphaZero jouer des millions de parties contre lui-même. A chaque partie, le programme ajustait chaque valeur de poids pour retenir "ce qui marchait le mieux".
Au début de ce processus, AlphaZero savait uniquement que le but du jeu était de mater, et quels coups il avait le droit de jouer. Imaginez un peu : en quelques heures, il a compris des principes comme le contrôle du centre ou l'attaque de minorité, simplement en voyant qui avait maté qui à la fin des parties précédentes ! Pendant cette phase d’apprentissage, les progrès d'AlphaZero étaient mesurés par des matchs avec une seconde par coup contre Stockfish, et contre la version préliminaire de lui-même. Cela semble incroyable, et pourtant, après seulement quatre heures à ce rythme, le programme en avait appris assez pour dépasser Stockfish au classement Elo, et tout cela en analysant seulement 0,1% du nombre de positions évaluées par Stockfish par seconde.
Bien que cela semble tout bonnement ahurissant, rappelez-vous que l'être humain a appris les échecs de la même manière. Pendant des siècles, des millions d'humains ont joué aux échecs, utilisant le réseau de leurs cerveaux pour mieux comprendre le jeu, comme un gigantesque multi-processeur de chair et d'os. Nous avons appris à la dure pourquoi il fallait jouer pour le contrôle du centre, mettre les tours sur les colonnes ouvertes, attaquer la chaîne de pions à sa base, etc... C'est ce qu'AlphaZero a du faire, lui aussi. Il serait fascinant de pouvoir voir les 44 millions de parties qu'il a joué contre lui-même. Je me demande à partir de laquelle il a découvert l'attaque de minorité ?
Comment AlphaZero joue aux échecs
Pour l'instant, nous avons vu comment AlphaZero améliore son réseau neuronal pour évaluer une position donnée et estimer les meilleurs coups à jouer (sans rien calculer).
Un peu de terminologie : la partie du réseau qui évalue les positions est appelée réseau de valeur, tandis que la partie qui "recommande les coups" est appelée réseau pratique. Voyons maintenant comment ces réseaux aident AlphaZero à jouer aux échecs.
Le gros problème des échecs, c'est l'explosion du nombre de variantes possibles. Calculer simplement deux coups à partir de la position de base demande de voir environ 150 000 positions, et ce chiffre croit exponentiellement à chaque coup. AlphaZero réduit considérablement le nombre de coups à calculer en ne considérant que ceux recommandés par son réseau pratique. Il utilise également son réseau de valeur pour arrêter de calculer des lignes lorsque l'évaluation finale est clairement décidée (gain/perte).
Admettons qu'il y ait une moyenne de trois coups potables à jouer dans chaque position, selon le réseau pratique. Malgré son taux très modeste de 80 000 positions analysées par secondes (qui lui permette néanmoins de voir sept coups en avance dans toutes les positions en une minute), l'évaluation instinctive de son réseau de valeur cible avec précision les variantes clefs à calculer, en faisant une machine de guerre ultra-puissante.
Le matériel qui permet de faire tourner AlphaZero
Sans surprise, le réseau neuronal d'AlphaZero tourne sur un matériel ultra-spécialisé : Le Tensor Processing Unit (TPU) de Google. AlphaZero a utilisé 5000 TPUs de première génération pour jouer contre lui-même, ce qui a permis de "former" son réseau, et 64 TPU de seconde générations pour l'entraînement proprement dit. Il s'agit là d'une puissance informatique formidable. Pour simplement jouer aux échecs, il n'a besoin que de quatre TPUs !
Pourquoi ne pas avoir utilisé les 5060 autres TPUs ? Probablement pour prouver qu'AlphaZero n'a pas besoin d'énormément de matériel pour fonctionner effectivement.

Un Tensor Processing Unit de Google (TPU).
Lorsque le réseau neuronal propage les valeurs à travers ses différentes couches, chaque données transmises à chaque neurone est multipliée par un certain poids. Il s'agit tout bonnement d'un produit matriciel (peut-être avez-vous déjà étudié cette notion à l'école !). Le TPU a été conçu par Google pour participer à l'apprentissage et au fonctionnement des réseaux neuronaux, et se spécialise donc en calcul de produit matriciel. Un produit matriciel que votre ordinateur personnel mettrait (très) longtemps à calculer peut être traité en un simple cycle de calcul par le TPU. (et le TPU de première génération opère 700 millions de cycles par seconde !). C'est comme comparer le rendement d'un robot géant mettant en bouteille 100 canettes de soda en même temps et d'un ouvrier les mettant en bouteille une par une (et moins vite).
AlphaZero contre Stockfish
Après quatre heures d'apprentissage, le classement d'AlphaZero avait déjà dépassé celui de Stockfish. Mais en s'entraînant encore cinq heures, il n'a pas pu s'améliorer significativement. (fait intéressant, les chercheurs de DeepMind n'ont d'ailleurs pas commenté cette observation). C'est alors que s'est engagé un match en 100 parties entre les deux programmes, chacun disposant d'une minute par coup. Le match s'est soldé par une large victoire d'AlphaZero : 64-36 sans la moindre défaite. Un résultat qui peut sembler sévère, mais qui statistiquement correspond en fait seulement à un écart de 100 points Elo. Beaucoup d'encre a coulé sur l'équité (ou plutôt la partialité supposé) du match, ce qui est fréquent lors des rencontres entre programmes. Stockfish utilisait 64 fils d’exécution, ce qui suggère qu'il tournait sur un ordinateur très puissant, mais ne disposait d'une fonction de hachage que d'un modeste GigaByte. En face, AlphaZero disposait de 5064 TPUs, mais ne fit usage que de quatre d'entre eux pour le match.
Nombreux sont ceux qui ont proposé d'organiser un match plus équitable entre les deux entités, mais ce n'est pas vraiment possible, car elles fonctionnent sur des matériels radicalement différents. C'est comme si, dans une course entre un homme et un cheval, on n'autorisait le cheval qu'à courir sur ses pattes arrières !
En revanche, ce qui est indéniable, et ô combien impressionnant, c'est que cette combinaison matérielle et logicielle a permis à AlphaZero d'apprendre en quatre heures seulement à évaluer les positions et les coups mieux que Stockfish, pourtant raffiné depuis des années.
Ne restez pas focalisés sur la fonction de hachage accordée à Stockfish, ce serait passer à côté de l'essentiel. Formulons-le ainsi : l'exploit d'AlphaZero aurait été à peine moins incroyable s'il avait perdu face à Stockfish sur un score de 36 à 64.
Je veux AlphaZero sur mon PC !
Non, ce n'est pas ce que vous voulez. AlphaZero forme des réseaux neuronaux. Ce que vous voulez, ce sont les réseaux neuronaux formés par AlphaZero ! C'est comme votre bronchite, que vous préférerez sans doute confier à un médecin qu'à un amphi de fac de médecine, n'est-ce pas ? Il ne fait aucun doute que ce réseau neuronal a été sauvegardé sur disque dur, tandis que les TPUs qui ont servi à son apprentissage ont été affectés à d'autres tâches. Si la structure du réseau et ses poids étaient publiés, il serait, en tout cas en théorie, possible de recréer un réseau similaire à AlphaZero sur son ordinateur personnel, mais ses performances ne seraient pas au niveau de celles atteintes avec le matériel spécialisé de Google.
Quel serait l'écart ? Calculons cela très approximativement : La partie de votre ordinateur la plus adapté aux calculs opérés par AlphaZero est le GPU, ou processeur graphique. Cela peut sembler étrange, mais ce matériel fait principalement du calcul de produit matriciel, tout comme un réseau neuronal.
Google estime que son TPU est environ 20 fois plus rapide qu'un processeur graphique moderne, la machine à 4 TPUs ayant battu Stockfish disposerait donc d'environ 80 fois la puissance d'un PC privé. Pour le moment, le programme n'est donc absolument pas adapté à une utilisation personnelle.
Une véritable révolution agite le monde de l'intelligence artificielle. Les réseaux neuronaux sont de plus en utilisés pour résoudre des problèmes qui apparaissaient comme insolubles par les moyens informatiques standards. L'approche généraliste d'AlphaZero lui a ainsi permis d'apprendre tout seul à jouer aux échecs (et pas juste à calculer des variantes) bien mieux que toutes les approches spécialisées qui l'ont précédé. Et cet exploit, il l'a réussi aussi au Go et au Shogi, des jeux plus complexes que les échecs pour les machines. Il est peu probable que Google continue à s'intéresser aux échecs. La firme va sans doute maintenant s'attaquer à des challenges plus épineux... et surtout plus utiles !
Que cela signifie-t-il pour les échecs tels que nous les connaissons ? Un pas de géant a été franchi : la machine peut maintenant apprendre toute seule à jouer aux échecs à très, très haut niveau, en utilisant un processus similaire aux humains plutôt que sa simple puissance brute de calcul. C'est une étape qui met en péril notre notion même de supériorité humaine. Cette évolution va indubitablement avoir un effet sur le futur des programmes d'échecs, et il nous faudra sans doute admettre à l'avenir que les échecs les plus pertinents... sont ceux joués par les machines.
C'est vrai, le matériel nécessaire pour faire tourner AlphaZero ne sera pas accessible au public avant longtemps, mais n'oubliez pas que quand le gigantesque Deep Thought (ancêtre de Deep Blue) battit Bent Larsen en 1988, ses programmeurs étaient loin d'imaginer que les écoliers, trois décennies plus tard, pourrait bénéficier d'une puissance de calcul supérieure sur de simples téléphones portables !
Comme le dit l'expression consacrée : gardez l'esprit ouvert !
